Redis入门了解
我是 Redis
你好,我是 Redis,一个叫 Antirez 的男人把我带到了这个世界上。
说起我的诞生,跟关系数据库 MySQL 还挺有渊源的。
在我还没来到这个世界上的时候,MySQL 过的很辛苦,互联网发展的越来越快,它容纳的数据也越来越多,用户请求也随之暴涨,而每一个用户请求都变成了对它的一个又一个读写操作,MySQL 是苦不堪言。尤其是到 “双 11”、“618“这种全民购物狂欢的日子,都是 MySQL 受苦受难的日子。
据后来 MySQL 告诉我说,其实有一大半的用户请求都是读操作,而且经常都是重复查询一个东西,浪费它很多时间去进行磁盘 I/O。
后来有人就琢磨,是不是可以学学 CPU,给数据库也加一个缓存呢?于是我就诞生了!
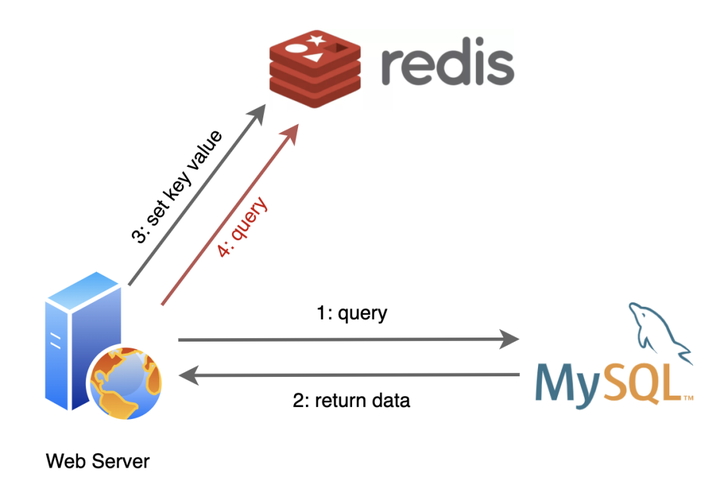
出生不久,我就和 MySQL 成为了好朋友,我们俩常常携手出现在后端服务器中。
应用程序们从 MySQL 查询到的数据,在我这里登记一下,后面再需要用到的时候,就先找我要,我这里没有再找 MySQL 要。
为了方便使用,我支持好几种数据结构的存储:
- String
- Hash
- List
- Set
- SortedSet
- Bitmap
- ······
因为我把登记的数据都记录在内存中,不用去执行慢如蜗牛的 I/O 操作,所以找我要比找 MySQL 要省去了不少的时间呢。
可别小瞧这简单的一个改变,我可为 MySQL 减轻了不小的负担!随着程序的运行,我缓存的数据越来越多,有相当部分时间我都给它挡住了用户请求,这一下它可乐得清闲自在了!
有了我的加入,网络服务的性能提升了不少,这都归功于我为数据库挨了不少枪子儿。
缓存遇到的几个问题
¶缓存过期 && 缓存淘汰
不过很快我发现事情不妙了,我缓存的数据都是在内存中,可是就算是在服务器上,内存的空间资源还是很有限的,不能无节制的这么存下去,我得想个办法,不然吃枣药丸。
不久,我想到了一个办法:给缓存内容设置一个超时时间,具体设置多长交给应用程序们去设置,我要做的就是把过期了的内容从我里面删除掉,及时腾出空间就行了。
超时时间有了,我该在什么时候去干这个清理的活呢?
最简单的就是定期删除,我决定 100ms 就做一次,一秒钟就是 10 次!
我清理的时候也不能一口气把所有过期的都给删除掉,我这里面存了大量的数据,要全面扫一遍的话那不知道要花多久时间,会严重影响我接待新的客户请求的!
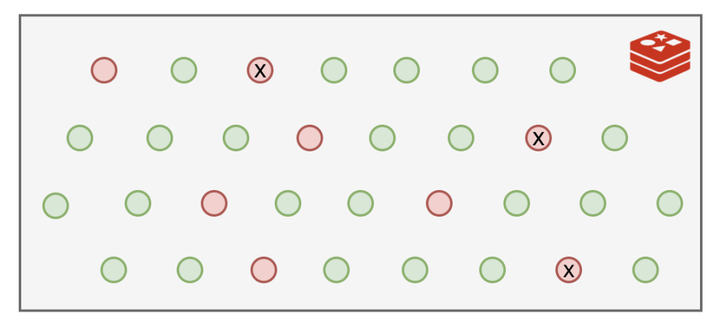
时间紧任务重,我只好随机选择一部分来清理,能缓解内存压力就行了。
就这样过了一段日子,我发现有些个键值运气比较好,每次都没有被我的随机算法选中,每次都能幸免于难,这可不行,这些长时间过期的数据一直霸占着不少的内存空间!气抖冷!
我眼里可揉不得沙子!于是在原来定期删除的基础上,又加了一招:
那些原来逃脱我随机选择算法的键值,一旦遇到查询请求,被我发现已经超期了,那我就绝不客气,立即删除。
这种方式因为是被动式触发的,不查询就不会发生,所以也叫惰性删除!
可是,还是有部分键值,既逃脱了我的随机选择算法,又一直没有被查询,导致它们一直逍遥法外!而于此同时,可以使用的内存空间却越来越少。
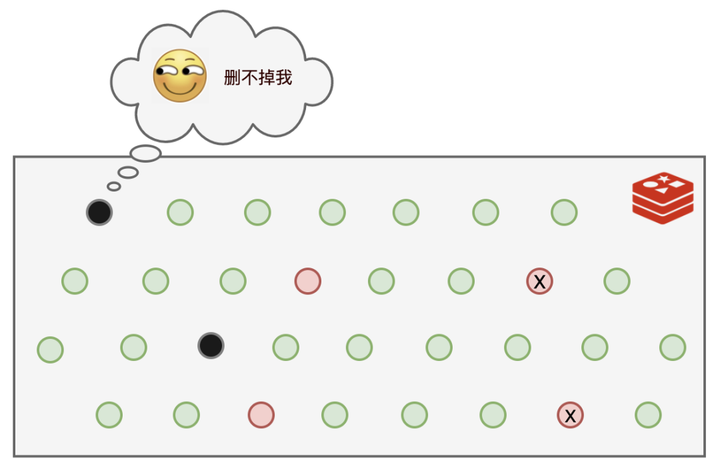
而且就算退一步讲,我能够把过期的数据都删除掉,那万一过期时间设置的很长,还没等到我去清理,内存就吃满了,一样要吃枣药丸,所以我还得想个办法。
我苦思良久,终于憋出了个大招:内存淘汰策略,这一次我要彻底解决问题!
我提供了 8 种策略供应用程序选择,用于我遇到内存不足时该如何决策:
- noeviction:返回错误,不会删除任何键值
- allkeys-lru:使用 LRU 算法删除最近最少使用的键值
- volatile-lru:使用 LRU 算法从设置了过期时间的键集合中删除最近最少使用的键值
- allkeys-random:从所有 key 随机删除
- volatile-random:从设置了过期时间的键的集合中随机删除
- volatile-ttl:从设置了过期时间的键中删除剩余时间最短的键
- volatile-lfu:从配置了过期时间的键中删除使用频率最少的键
- allkeys-lfu:从所有键中删除使用频率最少的键
有了上面几套组合拳,我再也不用担心过期数据多了把空间撑满的问题了~
¶缓存穿透 && 布隆过滤器
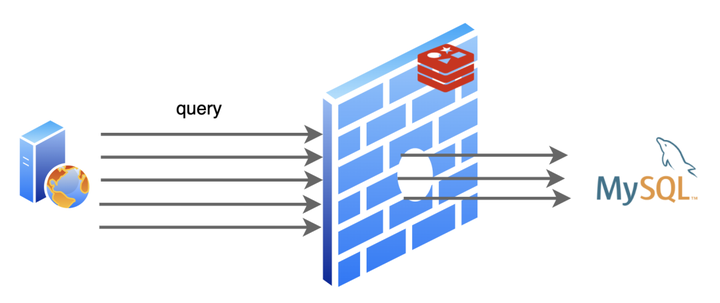
我的日子过的还挺舒坦,不过 MySQL 大哥就没我这么舒坦了,有时候遇到些烦人的请求,查询的数据不存在,MySQL 就要白忙活一场!不仅如此,因为不存在,我也没法缓存啊,导致同样的请求来了每次都要去让 MySQL 白忙活一场。我作为缓存的价值就没得到体现啦!这就是人们常说的缓存穿透。
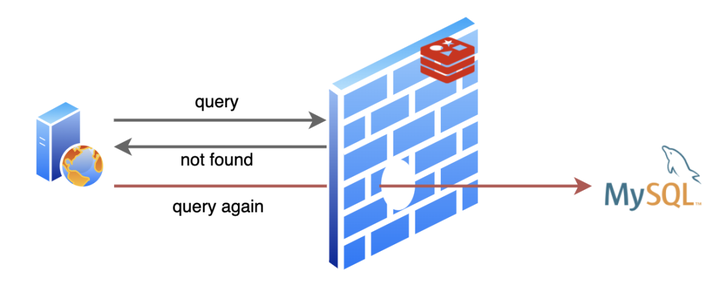
这一来二去,MySQL 大哥忍不住了:“唉,兄弟,能不能帮忙想个办法,把那些明知道不会有结果的查询请求给我挡一下”
这时我想到了我的另外一个好朋友:布隆过滤器
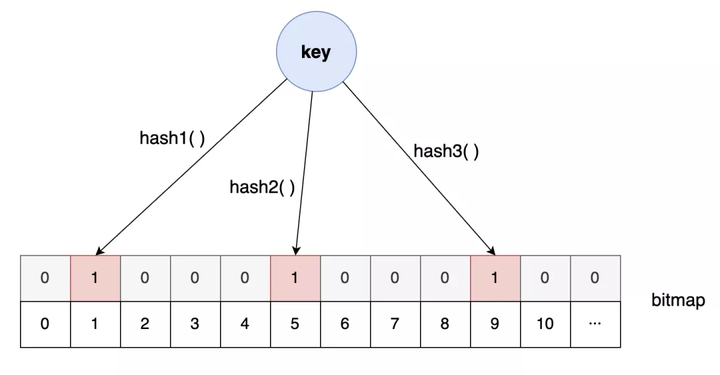
我这位朋友别的本事没有,就擅长从超大的数据集中快速告诉你查找的数据存不存在(悄悄告诉你,我的这位朋友有一点不靠谱,它告诉你存在的话不能全信,其实有可能是不存在的,不过它他要是告诉你不存在的话,那就一定不存在)。
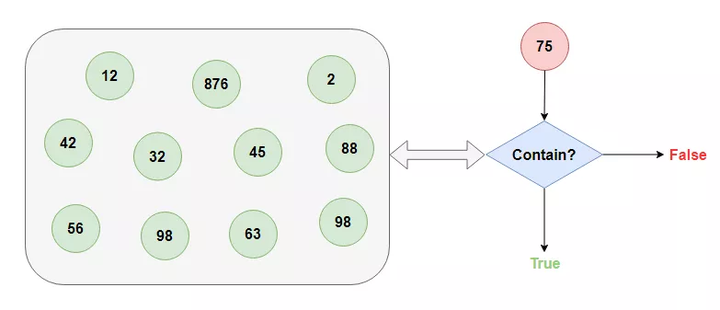
如果你对我这位朋友感兴趣的话,可以看看这里《白话布隆过滤器 BloomFilter》。
我把这位朋友介绍给了应用程序,不存在的数据就不必去叨扰 MySQL 了,轻松帮忙解决了缓存穿透的问题。
¶缓存击穿 && 缓存雪崩
这之后过了一段时间太平日子,直到那一天 ···
有一次,MySQL 那家伙正优哉游哉的摸鱼,突然一大堆请求给他怼了过去,给他打了一个措手不及。
一阵忙活之后,MySQL 怒气冲冲的找到了我,“兄弟,咋回事啊,怎么一下子来的这么猛”
我查看了日志,赶紧解释到:“大哥,实在不好意思,刚刚有一个热点数据到了过期时间,被我删掉了,不巧的是随后就有对这个数据的大量查询请求来了,我这里已经删了,所以请求都发到你那里来了”
“你这干的叫啥事,下次注意点啊”,MySQL 大哥一脸不高兴的离开了。
这一件小事我也没怎么放在心上,随后就抛之脑后了,却没曾想几天之后竟捅了更大的篓子。
那一天,又出现了大量的网络请求发到了 MySQL 那边,比上一次的规模大得多,MySQL 大哥一会儿功夫就给干趴下了好几次!
等了好半天这一波流量才算过去,MySQL 才缓过神来。
“老弟,这一次又是什么原因?”,MySQL 大哥累的没了力气。
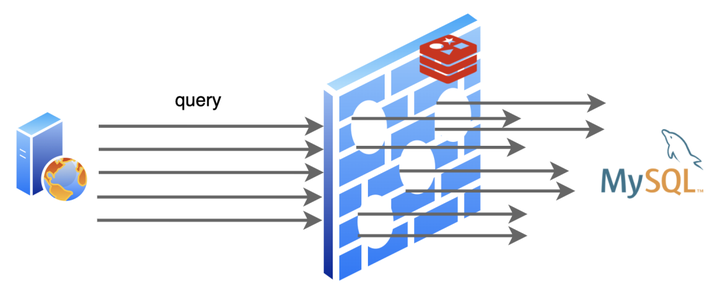
“这一次比上一次更不巧,这一次是一大批数据几乎同时过了有效期,然后又发生了很多对这些数据的请求,所以比起上一次这规模更大了”
MySQL 大哥听了眉头一皱,“那你倒是想个办法啊,三天两头折磨我,这谁顶得住啊?”
“其实我也很无奈,这个时间也不是我设置的,要不我去找应用程序说说,让他把缓存过期时间设置的均匀一些?至少别让大量数据集体失效”
“走,咱俩一起去”
后来,我俩去找应用程序商量了,不仅把键值的过期时间随机了一下,还设置了热点数据永不过期,这个问题缓解了不少。哦对了,我们还把这两次发生的问题分别取了个名字:缓存击穿和缓存雪崩。
我们终于又过上了舒适的日子 ···
断电了怎么办?持久化
那天,我正在努力工作中,不小心出了错,整个进程都崩溃了。
当我再次启动后,之前缓存的数据全都没了,暴风雨似的请求再一次全都怼到了 MySQL 大哥那里。
唉,要是我能够记住崩溃前缓存的内容就好了 ···
“快醒醒!快醒醒!”,隐隐约约,我听到有人在叫我。
慢慢睁开眼睛,原来旁边是 MySQL 大哥。
“我怎么睡着了?”
“嗨,你刚才是不是出现了错误,整个进程都崩溃了!害得一大堆查询请求都给我怼过来了!”,MySQL 说到。
刚刚醒来,脑子还有点懵,MySQL 大哥扶我起来继续工作。
“糟了!我之前缓存的数据全都不见了!”
“WTF?你没有做持久化吗?”,MySQL 大哥一听脸色都变了。
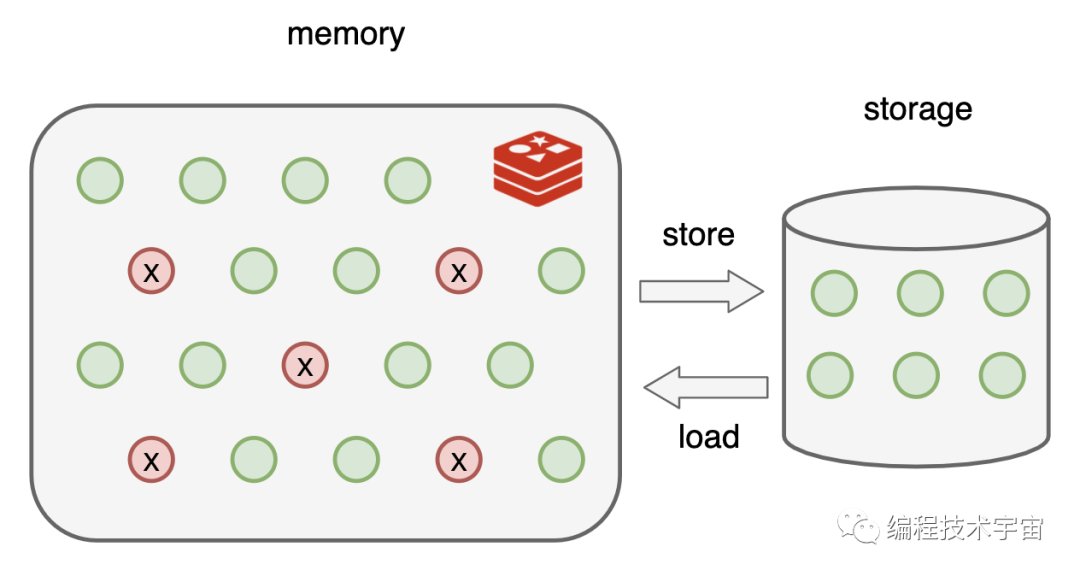
我尴尬的摇了摇头,“我都是保存在内存中的,所以才那么快啊”
“那也可以在硬盘上保存一下啊,遇到这种情况全部从头再来建立缓存,这不浪费时间嘛!”
我点了点头,“让我琢磨一下,看看怎么做这个持久化”。
¶RDB 持久化
没几天,我就拿出了一套方案:RDB
既然我的数据都在内存中存放着,最简单的就是遍历一遍把它们全都写入文件中。
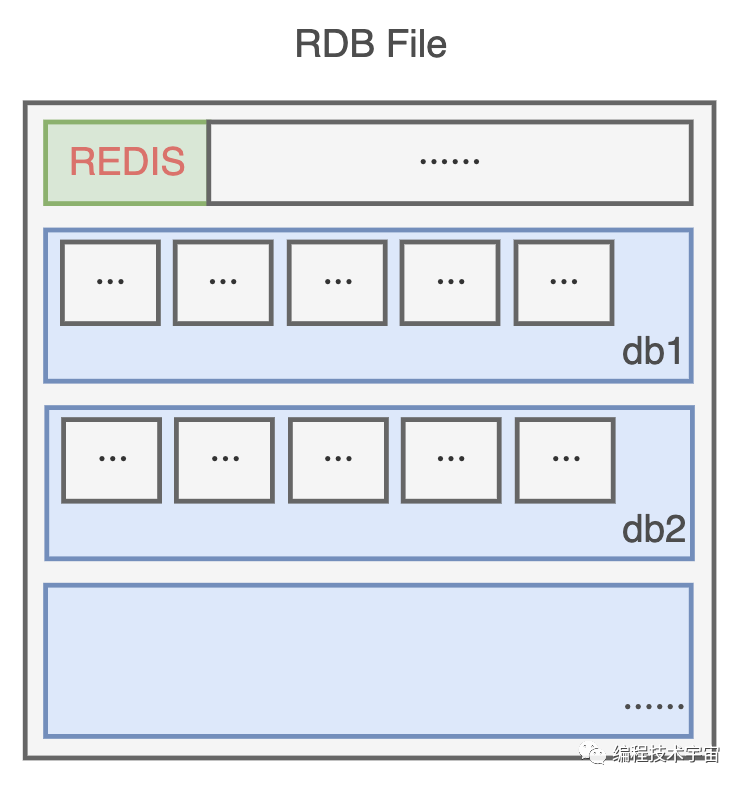
为了节约空间,我定义了一个二进制的格式,把数据一条一条码在一起,生成了一个 RDB 文件。
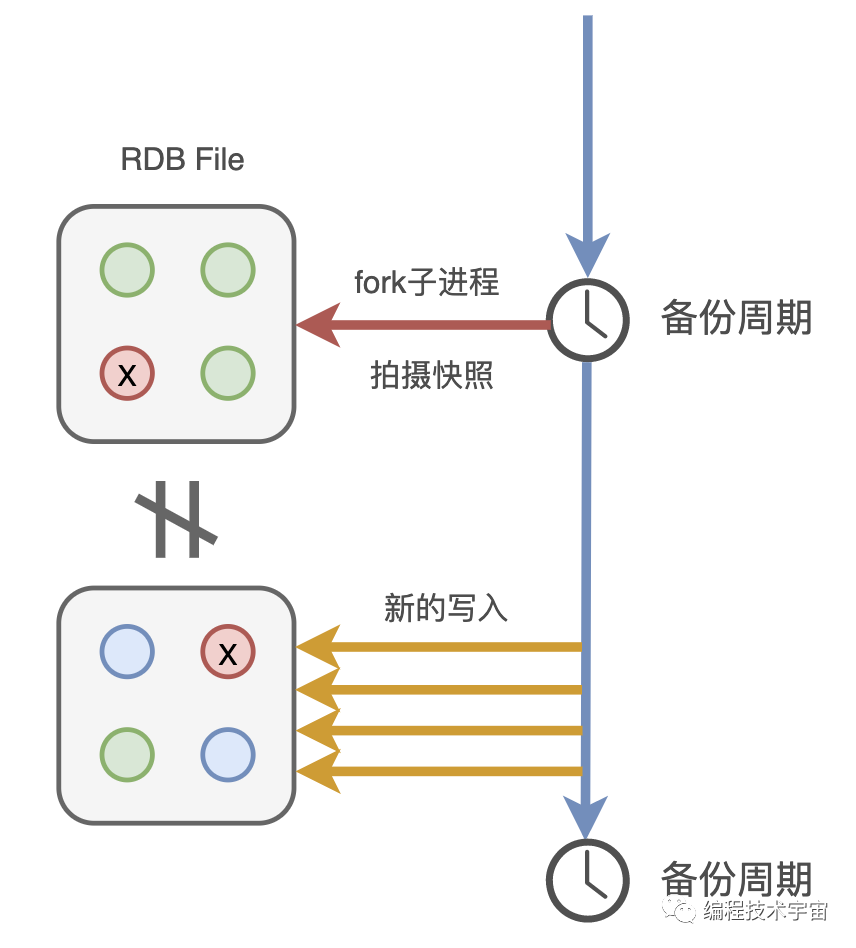
不过我的数据量有点大,要是全部备份一次得花不少时间,所以不能太频繁的去做这事,要不然我不用干正事了,光花时间去备份了。
还有啊,要是一直没有写入操作,都是读取操作,那我也不用重复备份,浪费时间。
思来想去,我决定提供一个配置参数,既可以支持周期性备份,也可以避免做无用功。
就像这样:
- save 900 1 # 900 秒(15 分钟)内有 1 个写入
- save 300 10 # 300 秒(5 分钟)内有 10 个写入
- save 60 10000 # 60 秒(1 分钟)内有 10000 个写入
多个条件可以组合使用,只要上面一个条件满足,我就会去进行备份。
后来我又想了一下,这样还是不行,我得 fork 出一个子进程去做这件事,不能浪费我的时间。
有了备份文件,下次我再遇到崩溃退出,甚至服务器断电罢工了,只要我的备份文件还在,我就能在启动的时候读取,快速恢复之前的状态啦!

¶MySQL: binlog
我带着这套方案,兴冲冲的拿给了 MySQL 大哥看了,期待他给我一些鼓励。
“老弟,你这个方案有点问题啊”,没想到,他竟给我浇了一盆冷水。
“问题?有什么问题?”
“你看啊,你这个周期性去备份,周期还是分钟级别的,你可知道咱们这服务每秒钟都要响应多少请求,像你这样不得丢失多少数据?”,MySQL 语重心长的说到。
我一下有些气短了,“可是,这个备份一次要遍历全部数据,开销还是挺大的,不适合高频执行啊”
“谁叫你一次遍历全部数据了?来来来,我给你看个东西”,MySQL 大哥把我带到了一个文件目录下:
- mysql-bin.000001
- mysql-bin.000002
- mysql-bin.000003
- ···
“看,这些是我的二进制日志 binlog,你猜猜看里面都装了些什么?”,MySQL 大哥指着这一堆文件说到。
我看了一眼,全是一堆二进制数据,这哪看得懂,我摇了摇头。
“这里面呀记录了我对数据执行更改的所有操作,像是 INSERT,UPDATE、DELETE 等等动作,等我要进行数据恢复的时候就可以派上大用场了”
听他这么一说,我一下来了灵感!告别了 MySQL 大哥,回去研究起新的方案来了。
¶AOF 持久化
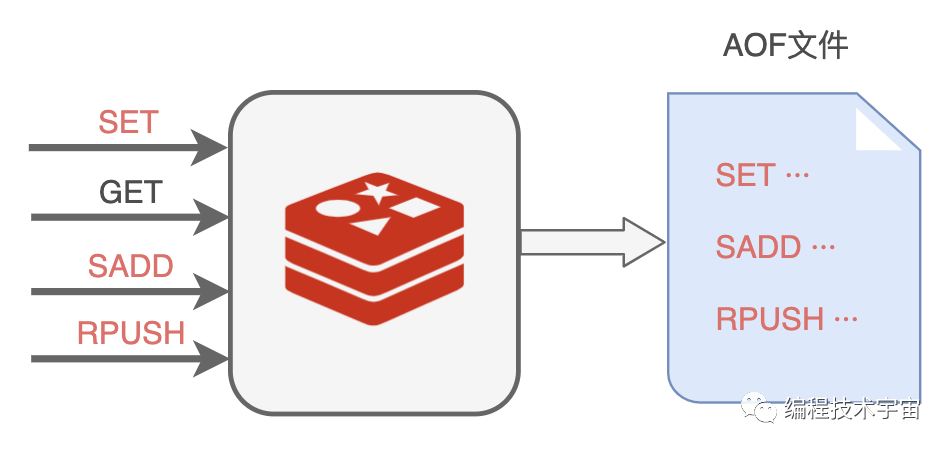
你们也知道,我也是基于命令式的,每天的工作就是响应业务程序发来的命令请求。
回来以后,我决定照葫芦画瓢,学着 MySQL 大哥的样子,把我执行的所有写入命令都记录下来,专门写入了一个文件,并给这种持久化方式也取了一个名字:AOF(Append Only File)。
不过我遇到了 RDB 方案同样的问题,我该多久写一次文件呢?
我肯定不能每执行一条写入命令就记录到文件中,那会严重拖垮我的性能!我决定准备一个缓冲区,然后把要记录的命令先临时保存在这里,然后再择机写入文件,我把这个临时缓冲区叫做 aof_buf。
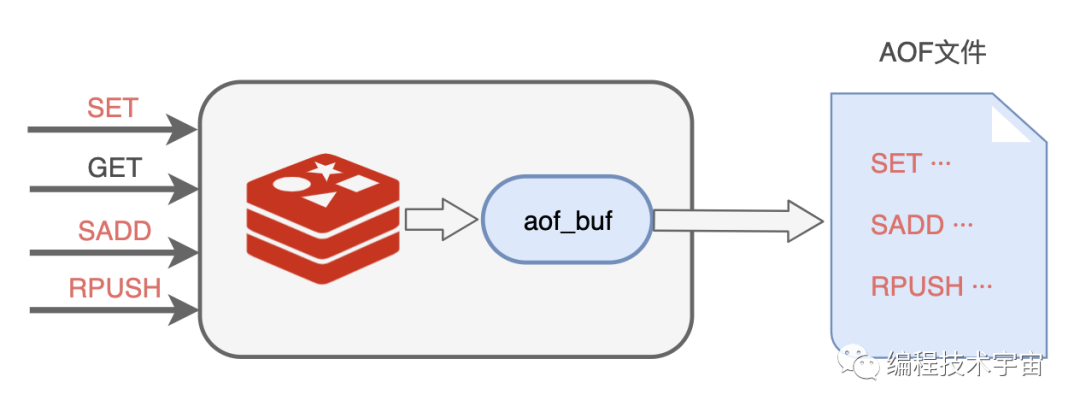
说干就干,我试了一下,竟然发现数据没有写入到文件中去。多方打听才知道,原来操作系统也有个缓存区,我写的数据被他缓存起来了,没有给我写入到文件中去,这不是坑爹呢嘛!
看来,我写完了还得要去刷新一下,把数据真正给写下去,思来想去,我还是提供一个参数,让业务程序去设置什么时候刷新吧。
appendfsync参数,三个取值:
- always: 每个事件周期都同步刷新一次
- everysec: 每一秒都同步刷新一次
- no: 我只管写,让操作系统自己决定什么时候真正写入吧
¶AOF 重写
这一次我不像之前那么冲动,我决定先试运行一段时间再去告诉 MySQL 大哥,免得又被他戳到软肋。
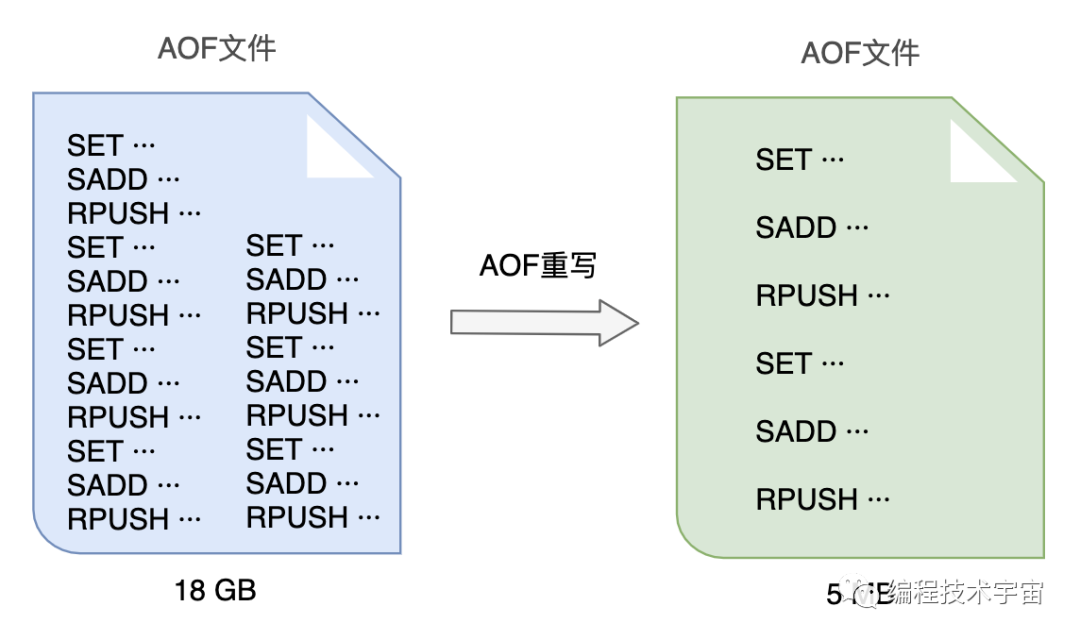
试用了一段时间,各方面都运行良好,不过我发现随着时间的推移,我写的这个 AOF 备份文件越来越大,越来越大!不仅非常占硬盘空间,复制移动,加载分析都非常的麻烦耗时。
我得想个办法把文件给压缩一下,我把这个过程叫做 AOF 重写。
一开始,我打算去分析原来的 AOF 文件,然后将其中的冗余指令去掉,来给 AOF 文件瘦瘦身,不过我很快放弃了这个想法,这工作量实在太大了,分析起来也颇为麻烦,浪费很多精力跟时间。
原来的一条条记录这种方式实在是太笨了,数据改来改去,有很多中间状态都没用,我何不就把最终都数据状态记录下来就好了?
比如:
- RPUSH name_list ‘编程技术宇宙’
- RPUSH name_list ‘帅地玩编程’
- RPUSH name_list ‘后端技术学堂’
可以合并成一条搞定:
- RPUSH name_list ‘编程技术宇宙’ ‘帅地玩编程’ ‘后端技术学堂’
AOF 文件重写的思路我是有了,不过这件事干起来还是很耗时间,我决定和 RDB 方式一样,fork 出一个子进程来做这件事情。
谨慎如我,发现这样做之后,子进程在重写期间,我要是修改了数据,就会出现和重写的内容不一致的情况!MySQL 大哥肯定会挑刺儿,我还得把这个漏洞给补上。
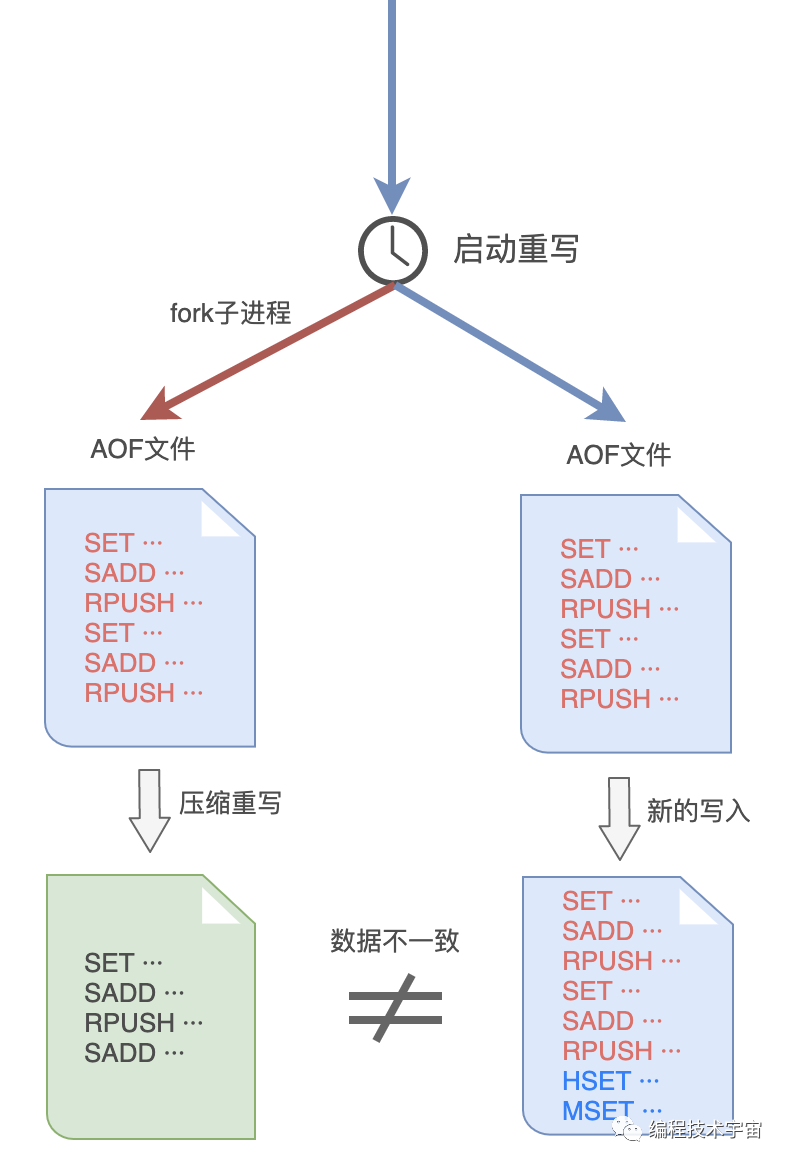
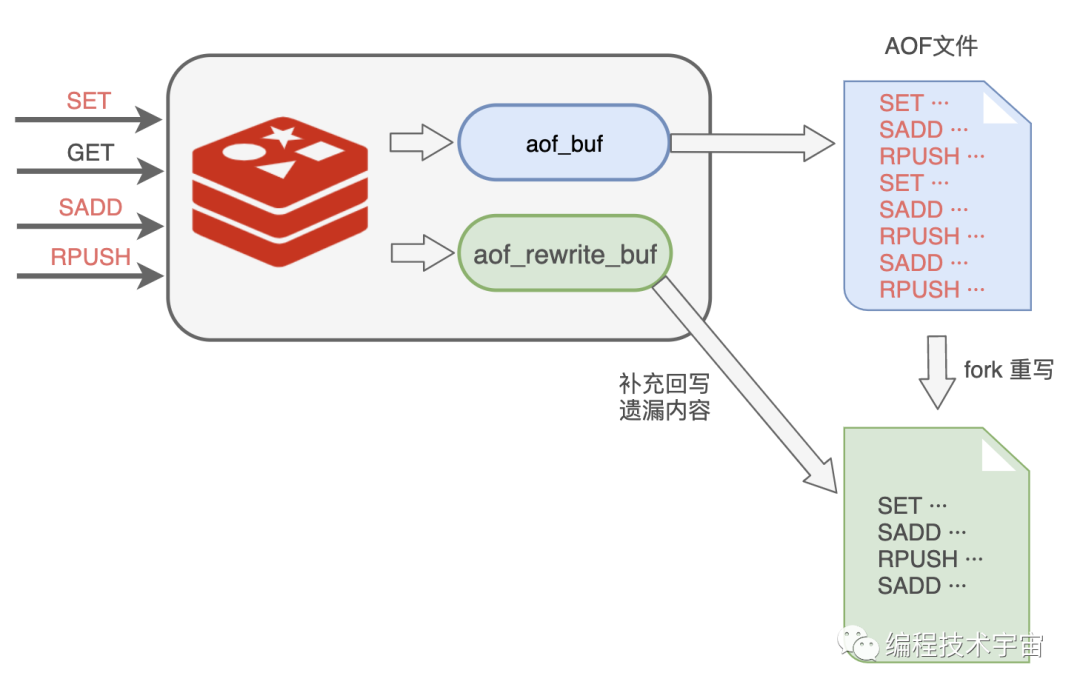
于是,我在之前的 aof_buf 之外,又准备了一个缓冲区:AOF 重写缓冲区。
从创建重写子进程开始的那一刻起,我把后面来的写入命令也 copy 一份写到这个重写缓冲区中,等到子进程重写 AOF 文件结束之后,我再把这个缓冲区中的命令写入到新的 AOF 文件中。
最后再重命名新的 AOF 文件,替换掉原来的那个臃肿不堪的大文件,终于大功告成!
再三确定我的思路没有问题之后,我带着新的方案再次找到了 MySQL 大哥,我都做到这份儿上了,这一次,想必他应该无话可说了吧?
MySQL 大哥看了我的方案露出了满意的笑容,只是问了一个问题:
这 AOF 方案这么好了,RDB 方案是不是可以不要了呢?
万万没想到,他居然问我这个问题,我竟陷入了沉思,你觉得我该怎么回答好呢?
RDB优点: 全量数据快照,文件小,恢复快。
RDB缺点:无法保存最后一次快照之后的数据。
AOF优点:可读性高适合保存增强数据,数据不易丢失。
AOF缺点:文件体积大,恢复时间长。
RDB-AOF混合持久化模式。
一个好汉,三个帮。高可用
“你怎么又崩溃了?”
“不好意思,又遇到 bug 了,不过不用担心,我现在可以快速恢复了!”
“那老崩溃也不是事儿啊,你只有一个实例太不可靠了,去找几个帮手吧!”
那天,Redis 基友群里,许久未见的大白发来了一条消息 ···

¶主从模式
于是,大白拉了一个新的群
以后的日子中,咱们哥仨相互配合,日常工作中最多的就是数据同步了
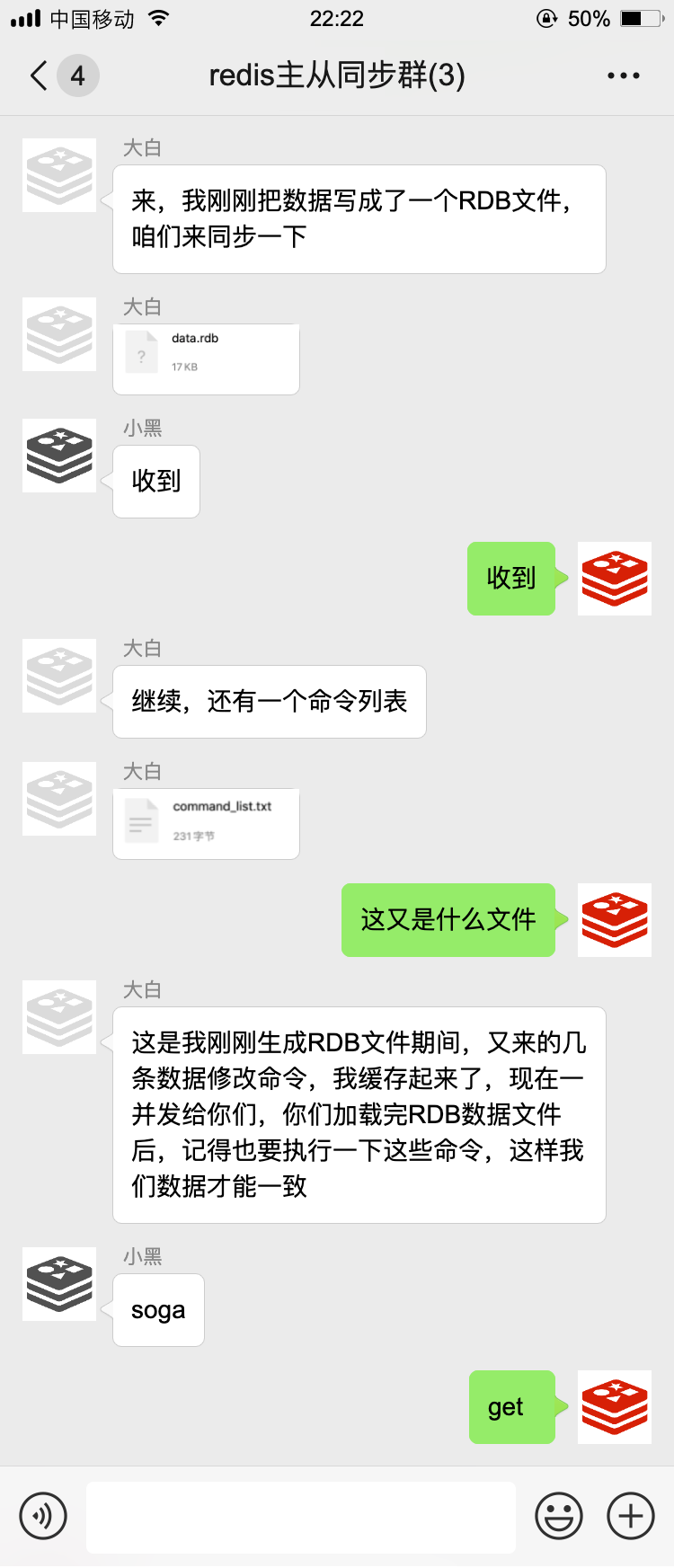
如果主节点有数据写入、删除、修改命令,也会把这些命令挨个通知到从节点,我们把这叫做命令传播。
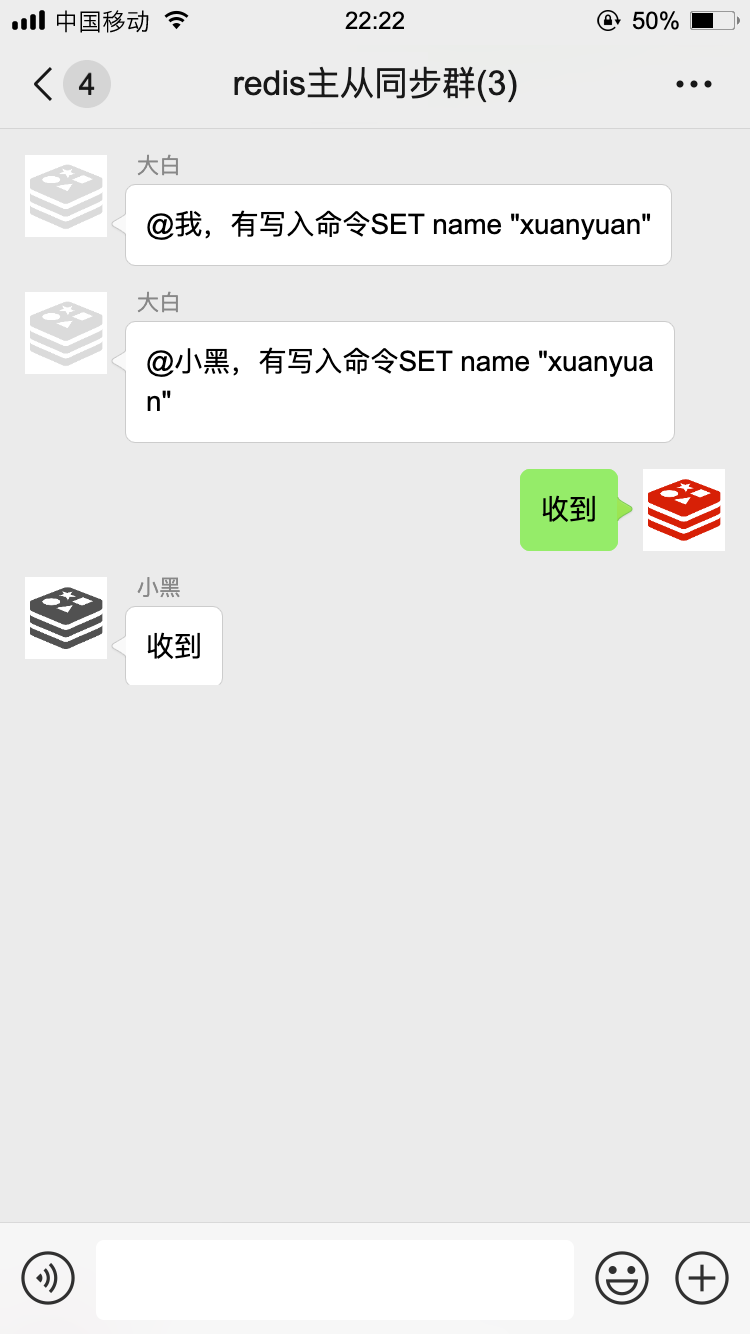
通过这样的方式,我们主节点与从节点之间数据就能保持同步了~
¶缓冲区、复制偏移量、运行ID
新的版本使用完整重同步和部分重同步 而部分重同步可以解决下面的问题
部分重同步分为三个部分:主服务器的复制偏移量、主服务器的复制积压缓冲区、服务器的运行ID。
如果主从服务器的复制偏移量不一样那么就去复制积压缓冲区查找,如果从的偏移量在缓冲区那么就进行部分重同步操作,
如果没有那么就进行完整重同步操作。
每个redis服务器都有自己的运行ID
断线重连后通过服务器运行ID判断重新连接的是否是之前的主服务器如果是则进行部分重同步操作
如果不是则进行完整重同步操作。
有一次,我不小心掉线了~
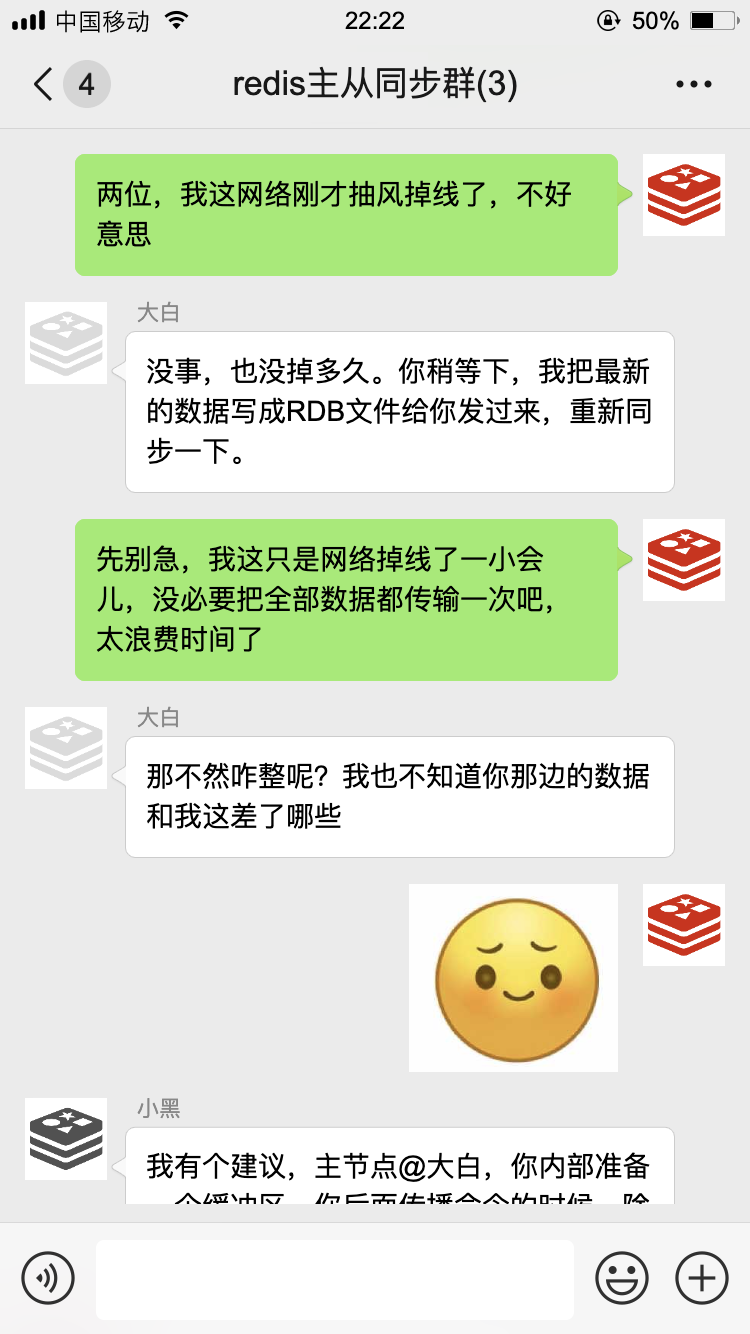

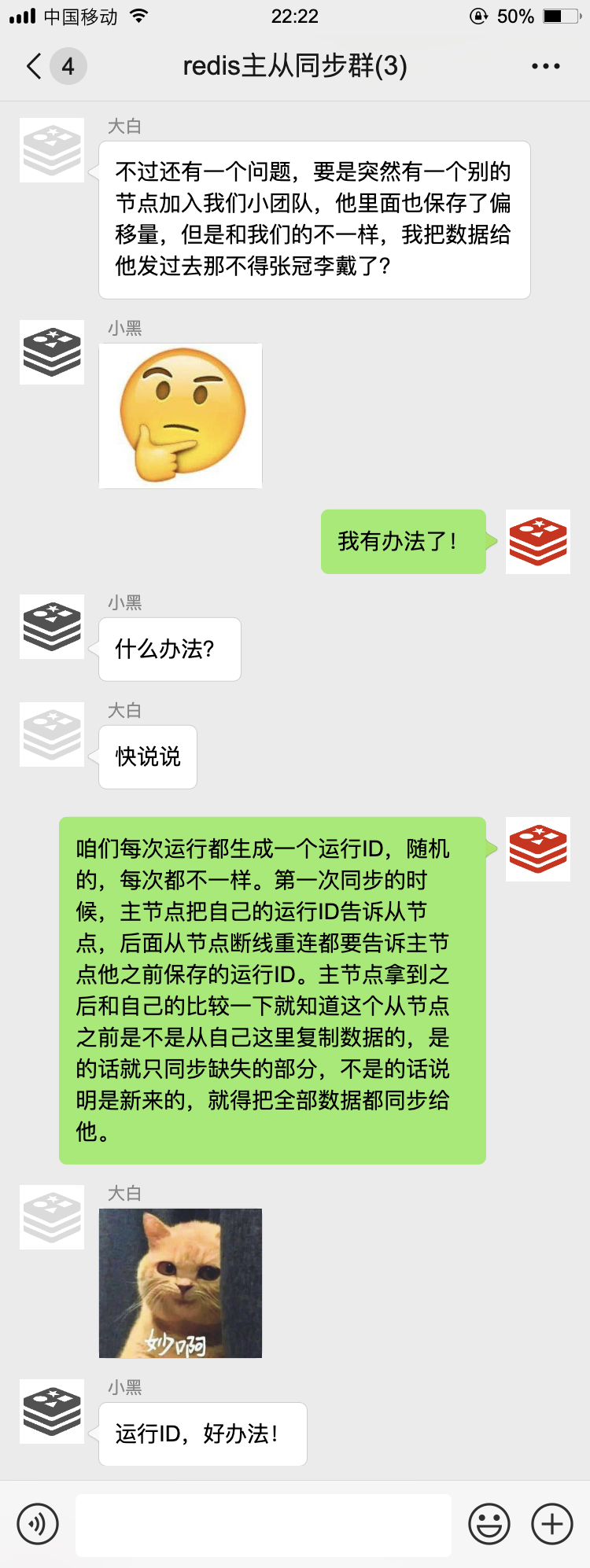
我们用上了新的数据同步策略,效率高了不少,就算偶尔掉个线,也能很快把缺失的数据给补上。
¶哨兵、主从切换
解决主从同步master宕机后的主从切换问题。
监控:检查主从服务器是否运行异常
提醒:通过API向管理员或者其他应用程序发送故障通知。
自动故障迁移:主从切换。
就这样过了一段时间 ···


新添了人手,我们准备大干一场!
为了及时获得和更新主从节点的信息,咱们哨兵每隔十秒钟就要用 INFO 命令去问候一下主节点,主节点会告诉我他有哪些从节点

为了更加及时知道大家是否掉线,咱们哨兵每隔一秒都要用 PING 命令问候一下群里的各个小伙伴:
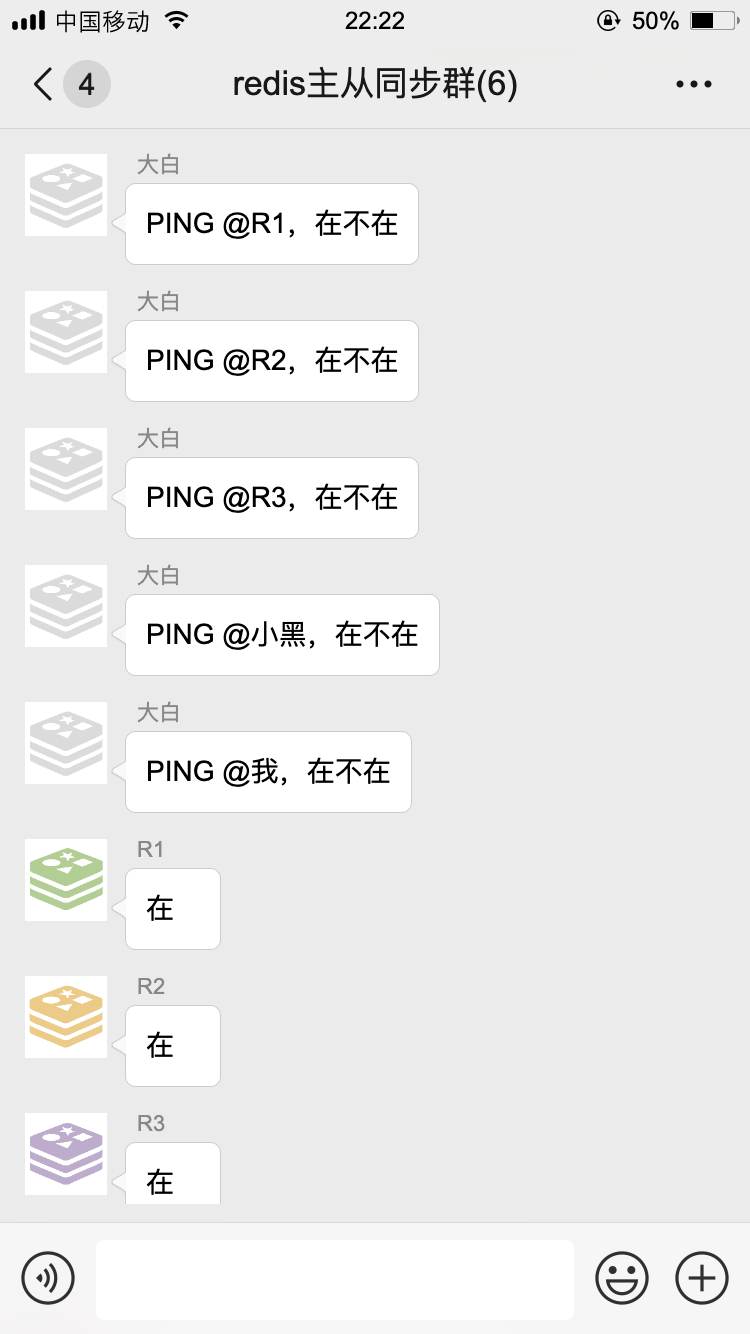
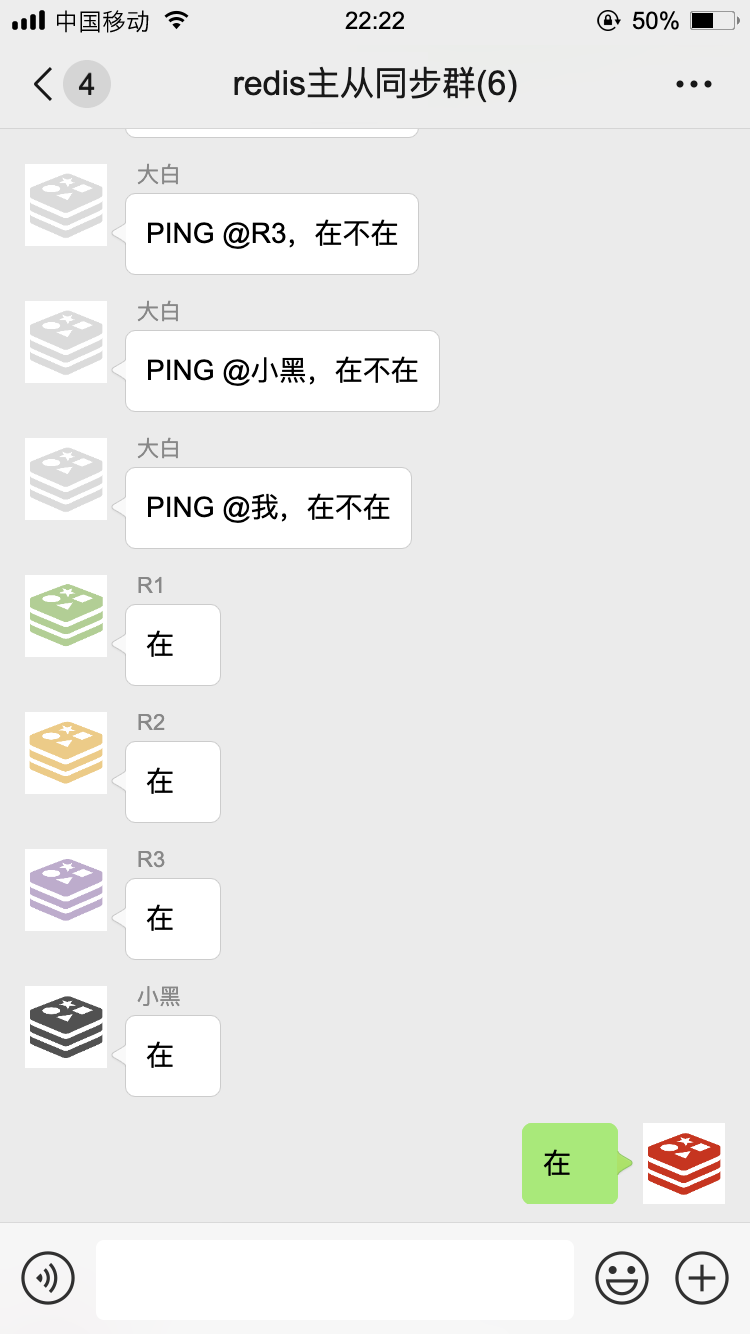
如果在设置的时间里没有收到回复,我就知道这家伙多半是跪了,就该启动故障转移了
不过这只是我的主观意见,光我一个人说了不算,为了防止误判,我还得去管理员小群里征求一下大家的意见:
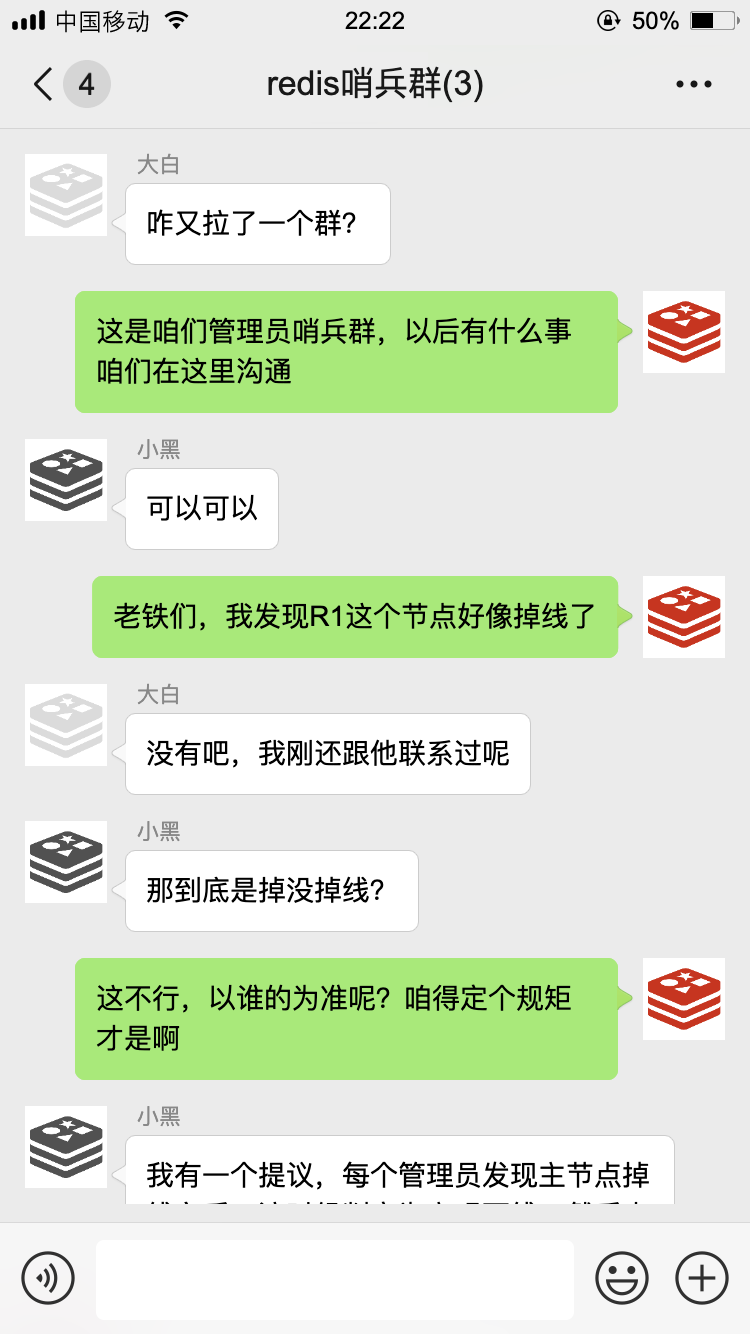

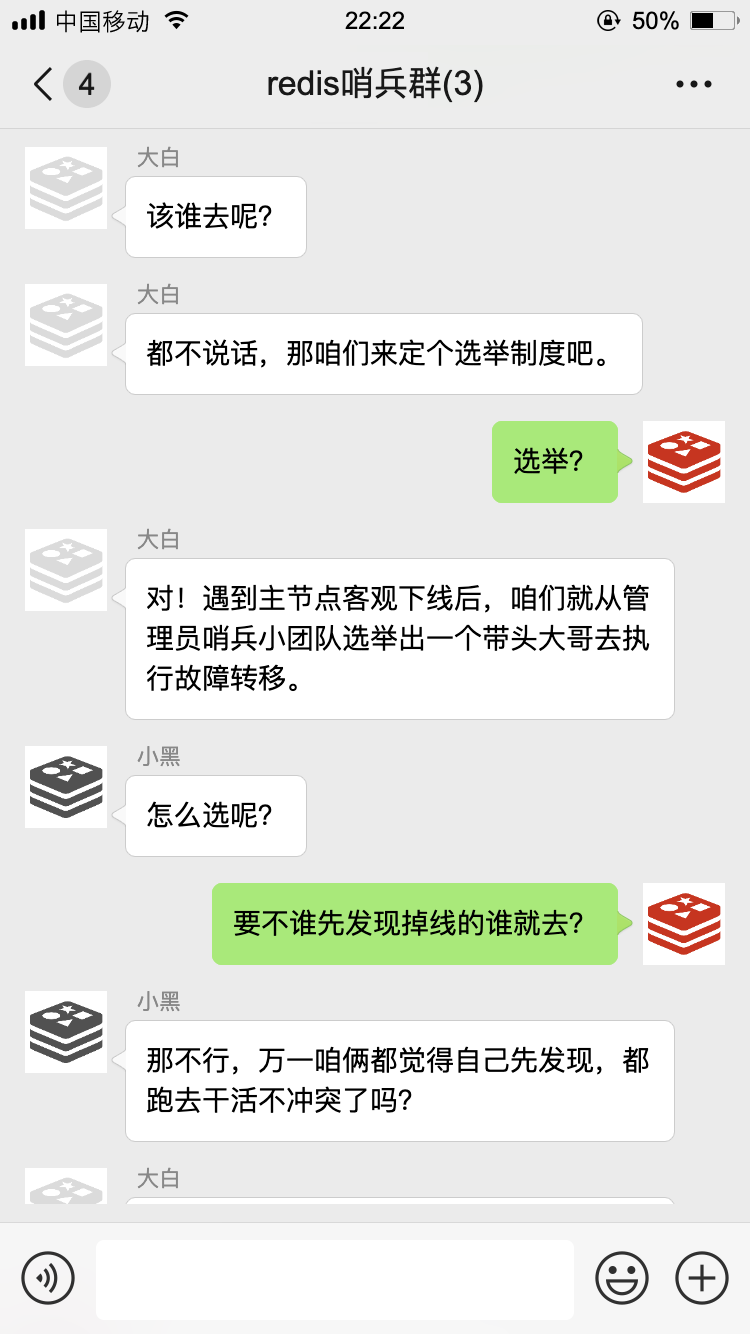

接下来,咱们就开始了第一次选举。
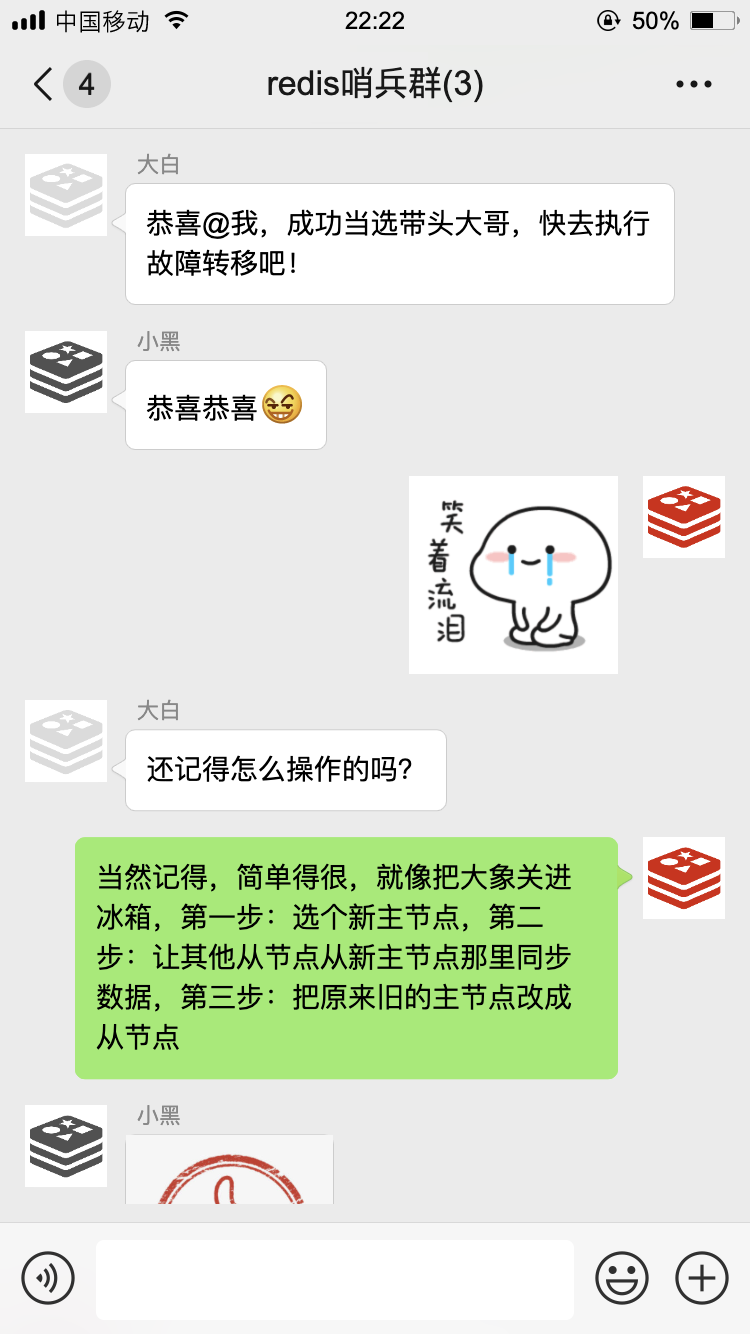


经过一番努力,我终于完成了故障转移,现在 R2 是主节点了。
不过没过多久,R1 又回来了:
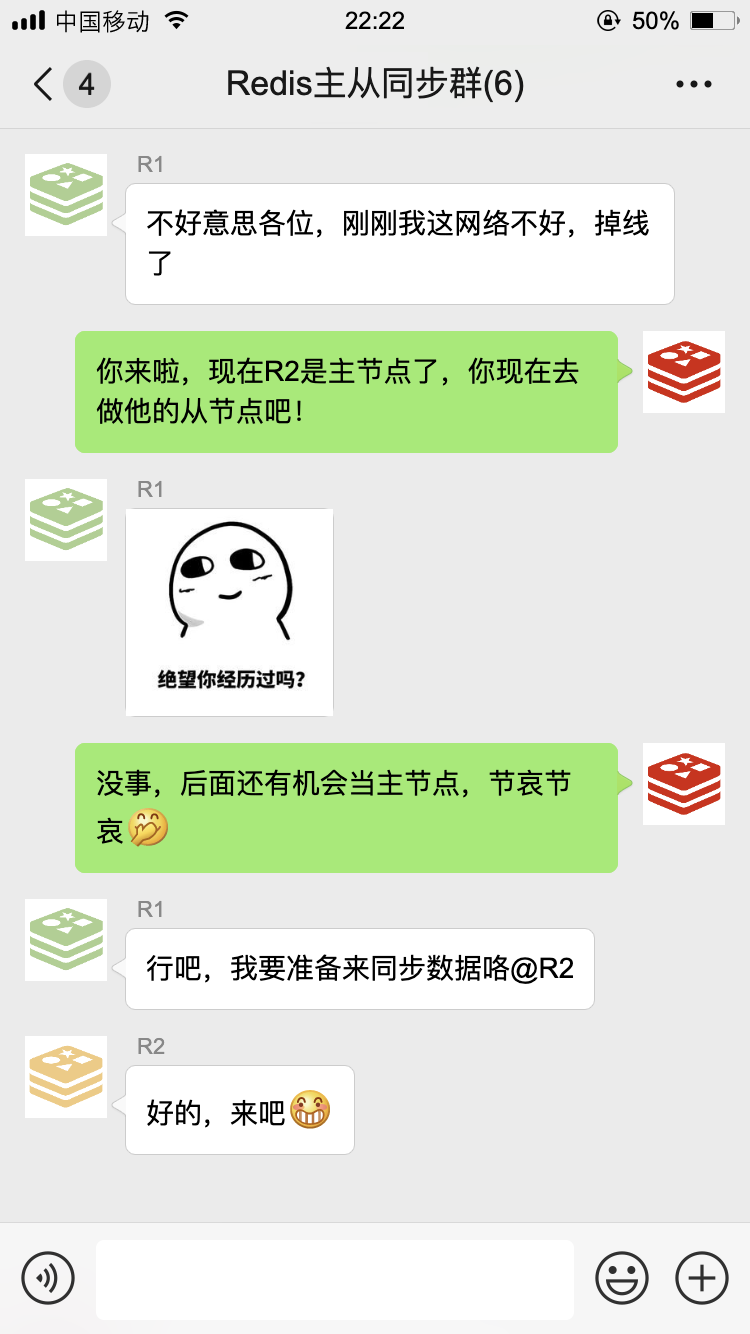
以上就是我们的日常工作了,通过咱们几个小伙伴的齐心协力,构成了一个高可用的缓存服务,MySQL 大哥再也不敢小瞧我们了。