分布式最佳实践:分布式锁
¶为什么
在传统的单体服务中,我们经常会遇到多线程对于单一资源的抢占导致的线程安全问题以及对数据库数据操作的一致性问题,如果是在单体系统中,我们可以很方便的使用编程语言提供的锁以及数据库事务来解决这些问题。
一旦单体系统转为分布式架构,那么本地事务和线程锁就无法满足跨进程的锁效果;分布式锁则是用于进程间同步访问共享资源的一种方式,通过全局共享来实现全局锁的效果,保证数据的一致性。
总的来说,在分布式系统中,当我们期望一个操作(一个请求、一个方法、一个数据库操作…)在整个系统中同一时间只能有一个线程执行,那我们就需要用到分布式锁; 抽象来看就是两个场景:
- 单一资源的数据变更:比如对共享存储数据(数据库、缓存…)进行修改,多线程的互斥
- access token:对于多个资源的原子性操作,期望整个业务逻辑就是单一线程执行保持一致性,在入口处就锁住
分布式锁应该具备的特性:
- 原子性:在分布式系统中,一个方法在同一时间只能被一个线程执行
- 阻塞性:在没获取到锁时可以进行阻塞也可以返回失败
- 高可用:能够正确的获取锁和释放锁,且具备锁失效的能力
- 高性能:获取锁与释放锁的性能保障
- 可重入:能够具备可重入特性
¶实现方式
¶基于数据库实现
¶乐观锁实现
先去干,能不能干,能不能干成先不管,这就是乐观心态。在开发过程中,乐观锁用的非常多,比如典型的 CAS ;在不加锁的情况下保证数据的一致性。
使用方式也很简单,只需要在表中添加一个版本号的字段,每次对数据进行修改的时候,通过版本来确定是否能够更新 update xx set version = OLD_VERSION+1 where id = ID and version = OLD_VERSION , 如果更新不成功,客户端可以选择是否重试。当然,需要加上索引。
可见这种方式的优势其实很明显,不加锁,使用简单。但也有一些局限性
- 只能支持单数据更新的一致性(对于数据的插入可以通过唯一索引来解决
- 由于是乐观锁(先干,在检查),也就意味着可能活干完咯,发现更新不了,浪费了计算资源
- 无法支持 access token
¶悲观锁实现
先自我审查自己能不能干,能不能干成,如果答案是no,那么就等着(阻塞)或先溜(返回),这就是悲观心态。悲观锁在 access token 模式更加适用。
使用方式同样很好理解(这只是基于数据库的悲观锁的一种实现方式)
- 有一张 资源锁 表,表中包含 锁 字段,并需要加上唯一索引
- 当有线程想要获取某个锁时,只需要在 资源锁 表中插入一条数据
- 如果插入成功,表示获取锁成功,插入失败则表示锁已经被占用
- 业务执行完释放锁,删除对应的锁记录即可
// 1. 创建资源锁表 |
乍一看好像很简单,如果程序一直保证正确执行,这种方式好像也行,但没如果… 对于一个分布式系统,服务宕机是会出现的,所以还需要考虑一些新的可能发生的问题
- 没有失效机制:持有锁的线程所在的服务宕机了,还没来的及释放锁怎么办? 可以通过在表中新增过期时间,写一个定时任务定期删除过期锁
- 不可重入:需要在表中新增线程信息,重入的时候先查询是否存在锁
- 不支持锁阻塞:需要编写相应的逻辑
- 基于数据库实现,那么数据库的可用性就需要得到保证,而且在并发大的时候,对于数据库的性能的影响问题
这么一分析…为了确保悲观锁的功能完整性,实现也会越来越复杂…以至于既然要用存储去实现,为撒不直接用缓存,性能至少有保障。
¶基于Redis :AP架构
既然想到存储用缓存来做,那必然想到的第一个就是 Redis 了,Redis 也很给力,可以很好的支撑分布式锁的能力,提供了比较好用的命令
setnx: 当且仅当 key 不存在,将 key 的值设为 value ,并返回1;若给定的 key 已经存在,则 SETNX 不做任何动作,并返回0。expire: 为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
大致的流程如下图
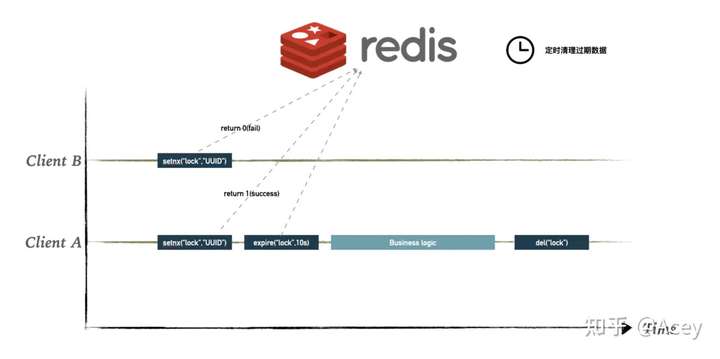
- client A 和 client B 同时执行
setnx("lock",UUID)尝试获取到锁,Redis 的实现保证了只会有一个 client 成功,假如 client A 运气好成功了 - client A 紧接着马上设置一个过期时间
expire("lock",10) - client A 继续执行业务逻辑
- 执行完业务逻辑后释放锁
如果程序能够正常走,好像也没什么问题…但我们知道分布式架构中,网络是不可靠的,如果在设置过期时间前 client B 挂掉咯,那就 GG 了,因为没有设置过期时间,那就成死锁了… 就像下面这样
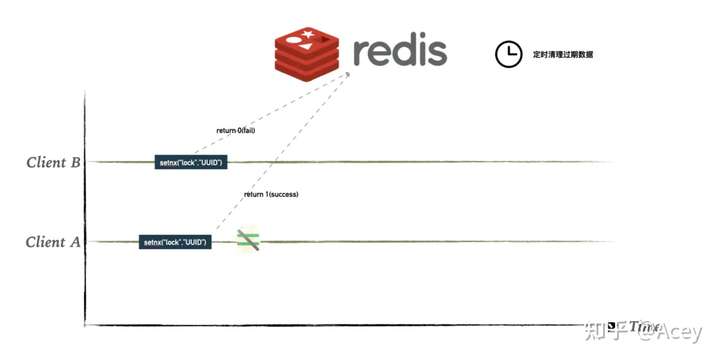
所以我们需要保证setnx和expire的原子性。在 Redis 2.6.12 之后增强了setnx命令,可以同时设置过期时间,从而保证原子性。
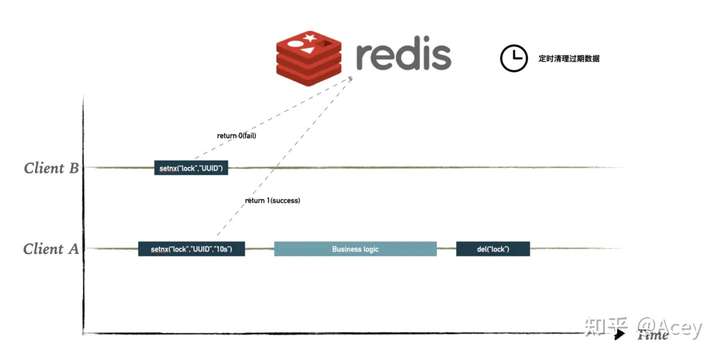
解决了死锁问题,再来看看过期时间的问题,我们如何判断我们应该设置多长时间的过期时间?
- 设置短了,业务逻辑可能还没执行完,锁被释放了,被其它线程获取执行
- 设置长了,需要业务逻辑处理完了自己释放锁(同样会存在线程挂掉的情况)
其实我们想要到达一种效果,如果能够自动续期,锁快要过期了,但是业务操作还没有处理完,就自动对锁进行续期。Java 中的 Redisson 客户端就通过 watch dog 机制(守护线程)来支持这个功能。
通过 Redisson 客户端获取锁时会创建一个守护线程,通过守护线程来定期 check 过期时间,如果业务逻辑还在运行,那么就会续时。如果程序宕机,那么守护线程也会一起挂掉,redis 中的锁也将不会再次续时,最后过期。从而自动实现续期且不会出现死锁的问题。
简单回顾一下,我们解决了
- 获取锁和设置过期时间的原子性问题
- 过期时间自动续时的问题
在单机模式下看起来已经没什么问题了。而在生产环境下一般都会是集群模式,比如哨兵模式。得益于 Redis 的 AP 架构,选择了可用性,使得其性能非常好,但也正是因为AP架构,可能会导致数据丢失的情况。
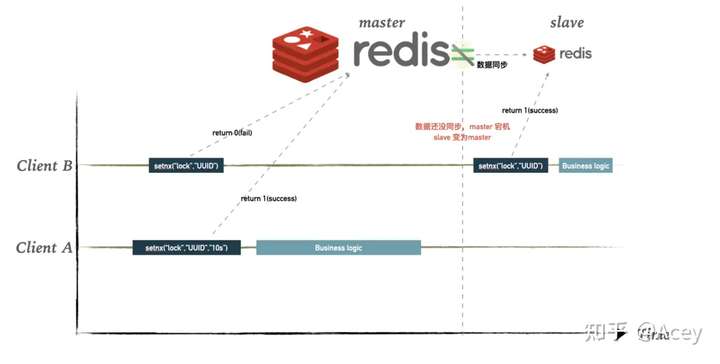
- client A 获取锁成功
- master 节点在同步锁信息到 slave 节点时,master 宕机,信息没有向 slave 节点同步成功
- slave 节点通过选举成为 master 节点
- client B 再次获取相同的锁,发现 slave 节点上并没有其它线程占用,所以也获取到了锁
- client A 和 client B 获取到了相同的锁
当然,这个是非常极端的情况下会出现的问题;虽然 Redis 之父 Antirez 提出来了分布式锁的一种 「健壮」 的实现算法 RedLock,但依旧还是会有新的问题,比如节点奔溃重启、时钟跳跃…
总的来看,基于 Redis 实现分布式锁是很常用的,性能也比较高,满足绝大部分业务场景,如果我们能够接受非常极端情况下带来的锁丢失问题,Redis 分布式锁是个很好的选择。
¶基于Zookeeper :CP 架构
Zookeeper 是一种提供「分布式服务协调」的中心化服务,是以 Paxos 算法为基础实现的。Zookeeper 采用的是 CP 架构,选择了强一致性,这也就意味着不会像 Redis 那样出现数据丢失的情况(主从切换时),但为了实现强一致性,那么性能肯定是要比 Redis 差一些。
使用 Zookeeper 来实现分布式锁是比较简单的
- client 会在 Zookeeper 中创建一个临时节点,比如`/zk/lock
- 如果获取成功,那么 client 会创建一个 session 保持和 Zookeeper 临时节点的关联
- client 处理业务逻辑
- client 处理完业务逻辑后删除 临时节点,关闭 session
如果 client 宕机,那么 session 就会结束,临时节点也会自动删除,其它 client 就可以创建 lock 节点。
session 的维护是依赖于 client 的定时心跳来维护的,也就是说,如果 client 没有及时的给 Zookeeper 发送心跳检查,那么 Zookeeper 就会认为这个 session 已经过期了,就会删除调临时节点。比如出现长时间的 GC 或者长时间的网络延迟,都可能会导致临时节点被删除的可能。
对于 Zookeeper 来说,实现分布式锁从使用者角度来看比较简单,不需要考虑太多的东西,比如过期时间的设置。但维护成本会比较高,性能相对 Redis 也会差一些,以及可能会出现长时间失联导致的节点数据丢失的问题。
¶总结
- 优先使用基于数据库的乐观锁
- 如果期望更高的性能且能够接受极少数情况的锁丢失,那么优先选择 Redis
- 如果期望尽可能的避免锁丢失,优先选择 Zookeeper,且考虑 GC 时间和 心跳检查的设置
- 在分布式系统中极端情况下,分布式锁都不太可靠,所以需要我们在业务层面的入口也相应的隔离,在真的发生了锁丢失导致的数据不一致的情况做对应的补偿